
Today we’ll talk about cases and solutions when Machine Learning (ML) as a Service doesn’t work. When this happens, your company shouldn’t start off with hiring a data scientist. The best option is to invest in a custom-made solution to solve your urgent business needs. Only then when you have a workable solution, can you dive into deep data science and create a proper team that can create an in-house data science solution.
- The time when you don’t need to hire data scientists and when you should start investing into data science resources.
- Start building a comprehensive data science product not from the research, but from the end-to-end solution that solves business problems.
- People envisage a data scientist that has a balance of knowledge in relative subject matters, but in real life, you can barely find such an ideal candidate.
- Make your data scientists successful and productive. Any team that deals with data science has to be cross-functional with adjacent roles contributing to the end solution.
- Deliver end-to-end solutions that solve business problems rather than research papers.
Custom made end-to-end solution as a start
Here we should talk about classical data science, where you have data, goals and you need to build models to solve a pressing issue. The best way to do this is to jumpstart such a process by putting together bits and pieces of some ready-made services into a single workable product and show your customer a clear-cut result shortly. This can be done without any complex or global research, and you can comfortably formulate specifications taking into account all the feedback from your customer and create a more high-level data science product in the long run.

One of the biggest issues for any data science project is in formulating the specifications for it. The usual request is “create something for my company using data science. Analyze data for me.” This type of a job has lots of trials and errors. And having some custom basic end-to-end solution from the start lets you insert into it the needed extra services on the go. This allows us to provide insights and predictions into a particular business workflow much easier.
I believe that you should start to build your system from the ground up not from the data research, but for an end-to-end solution. And then bit by bit you can take out and insert the required services in the process.

How to do data science research?
You start with employing a data scientist that matches your company’s needs. You can use the standard data scientist chart: this employee should have a firm footing in the application environment, mathematics, and programming. Their business skills are essential to success. I believe that an understanding of the topical area is critical here because we are solving business issues. And the data scientist that solves more academic problems will be more focused on winning a Kaggle competition than addressing the business needs. It is important that this person understands the product development cycle. This way he builds up models and analyses data in such a way that it would be possible to be deployed in production.
For example, if a person is using R (language and framework for data scientists) we should note that it is more aimed at research and it is not production ready. Correspondingly the results of such research cannot be deployed in any end-to-end solution. Therefore, he should take note of this and work in pair with a programmer. Although in the above diagram we see that the data scientist should have hacking skills, in reality, this is not the case. In their vast majority, data scientists are not able to write quality code. And if you need not just the research but a solution then process-wise you need to have a data scientist working together with a data engineer.
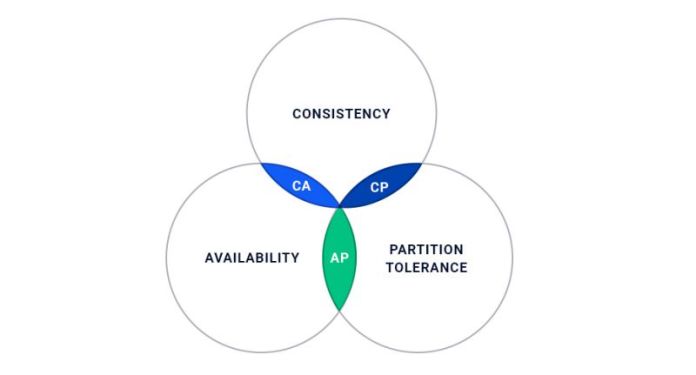
CAP theory as analogy
It is impossible to have three database properties at once: consistency, availability, and partition-tolerance. This is the basic rule know to all developers. And this applies to a data scientist as well, as people envisage a data scientist on the overlap of these subjects, but in real life, you cannot find such an ideal candidate. Usually, people tend to lean one or another way in their work and keeping a balance is not always a priority.
In principle one of the solutions that we use ourselves is that a data scientist should have business insights, understand the math behind it and work together in tandem with a skilled developer. Of course, a proper data scientist should be able to write any semblance of code. But a data scientist should work with a data engineer, write and realize code being both responsible for the quality and sustainability of this solution.
The classic tragedy of a company that decides to initiate any data science research is in when a data scientist says “I’ve got 40000 lines of Python code on my PC, can you make it work in production?” And, of course, this is virtually impossible to do. So you have an issue at hand that all of the research is simply wasted.

Cross-functional teams
Any team that deals with data science has to be cross-functional i.e. it has to cover a whole stack of the solutions it writes. In a common infrastructure, there should be present a DevOps engineer, data scientist, data engineer, and a product developer writing the web app and/or mobile app. And this is a single team that is responsible for the result. They should work together and solve related tasks that are interconnected in their interactions.
All of this means that the whole team is responsible for the business result. This applies also to the transitionary research done by a data scientist which is impossible to use in production on its own.

Old-school vs. Vertical teams
To dig in deeper, let’s take a classic old-school layered company organization structure when you have a department of data scientists, operations, UI developers, big data department, QA engineers and so on. In this case, we have every project penetrating most of these teams. And the classic problem is that tickets and tasks are being thrown around by one team to another, and the real business goals are being watered down along the way and not solved in the end. So instead of this horizontal division, we have divided the teams vertically. This allowed us to create teams that see a clear-cut goal they need to achieve. And at the same time, they can improve their cross-skills, and boost their responsibility levels.
As a result, such teams began to deliver, Scrum and Agile started to work properly. It is not directly related to data science, but nevertheless, there is a standard mistake of many companies where data scientists work somewhere at a university and write mostly academic papers. It is a topic for a whole new article, but for now, you need to distinguish that there is a data scientist and a production data scientist. And you should aim at employing the latter one within your teams, and not let a data scientist work alone remotely.
This guest contribution has been written by Stepan Pushkarev, Head of DevOps Practice at Squadex.com and CTO at Hydrosphere.io. The article was provided by Nikita Koval, Head of Content at Squadex.com.
Photo credit: Sebastiaan ter Burg